
Most people use ChatGPT or Claude without ever asking how they work. Here’s a high-level breakdown of how modern LLMs like GPT-4 operate:
At the core is a transformer architecture, a neural network model introduced in 2017 that doesn’t read text sequentially like an RNN — it looks at the entire sentence or document at once using self-attention. This mechanism lets the model determine which words matter most when predicting the next token.
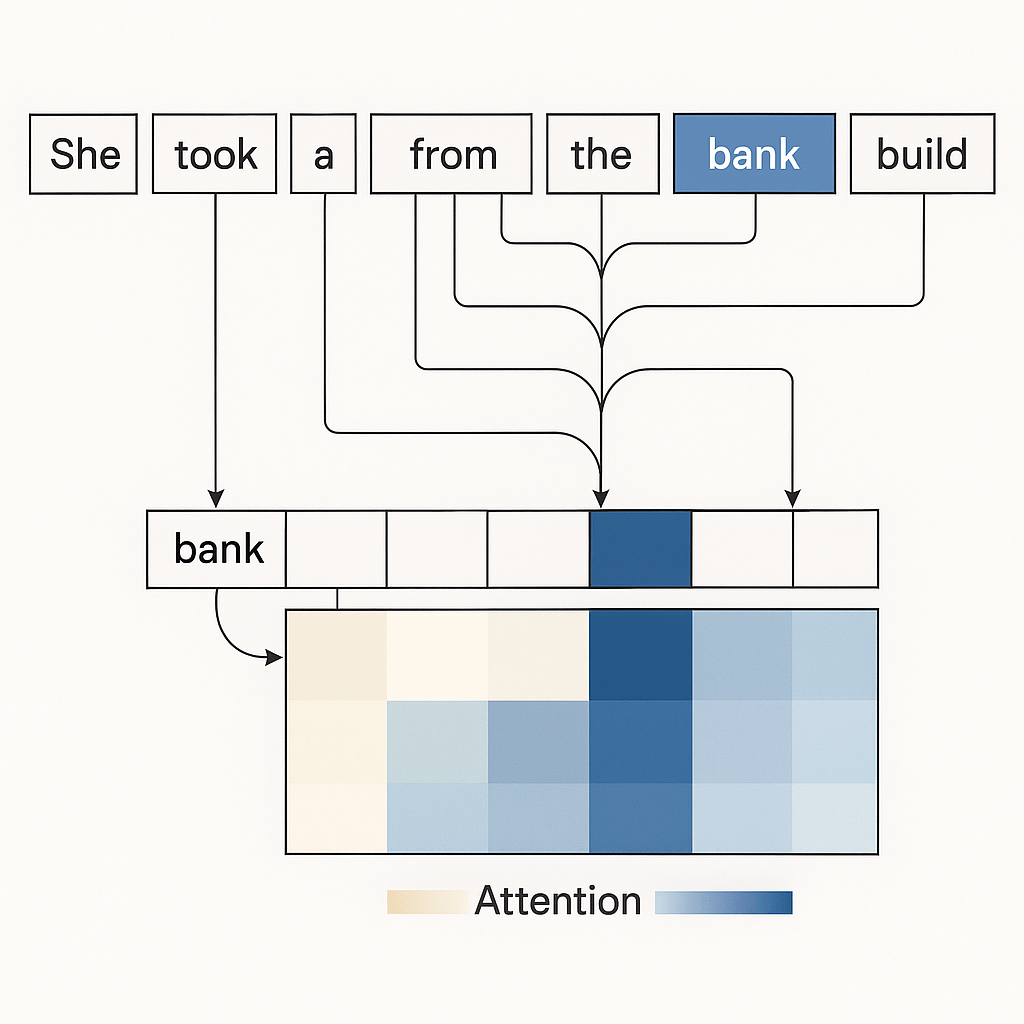
Self-attention allows language models to weigh the importance of surrounding words—here, “bank” attends more to “loan” than to unrelated terms.
Text gets broken down into tokens (subword units), which are converted into high-dimensional vectors via an embedding layer. These vectors pass through layers of multi-head self-attention, feed-forward networks, and normalization — repeated dozens or even hundreds of times depending on model depth.
During training, the model learns to predict the next token in a sequence, using a process called causal language modeling. It sees billions of text sequences and updates its weights using backpropagation and gradient descent to minimize prediction error.
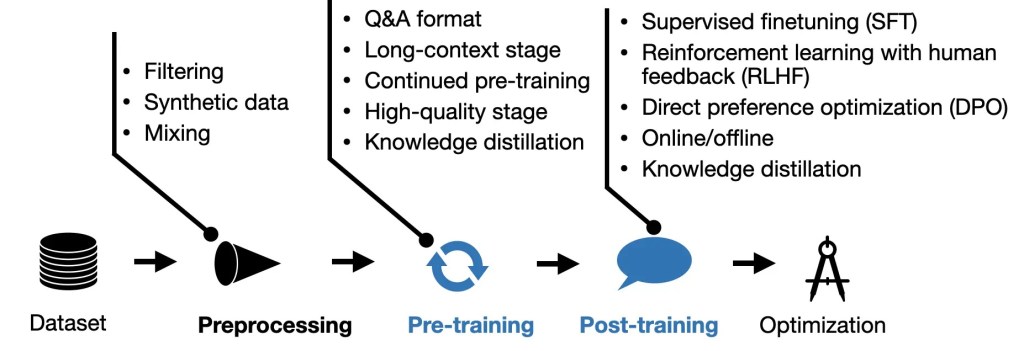
After pretraining, the model undergoes alignment (like Reinforcement Learning from Human Feedback — RLHF) to better follow instructions, avoid harmful outputs, and behave in a conversational way.
At inference time, the process reverses: you input a prompt, it gets tokenized, run through the network, and the model outputs the most likely next token — one at a time — until the answer is complete.
It’s not magic. It’s math at scale.


Leave a comment