

LLMs are undeniably powerful. In the span of just a few years, they’ve gone from quirky autocomplete tools to high-functioning assistants capable of writing code (sort of), analyzing contracts, and passing medical exams (which isn’t really how I want my doctor to pass the boards). But they still have a fundamental flaw that limits their usefulness and trustworthiness: they hallucinate.

Ask an LLM to cite a study, explain a legal precedent, or even describe a biological process, and there’s a decent chance it will make something up. Not maliciously—but because it’s just doing what it was designed to do: predict the next word based on patterns in its training data. That’s the core of the problem. These models are incredibly good at language, but they don’t “know” anything in the way humans or even traditional knowledge systems do. They lack structure.
That’s where knowledge trees and ontologies come in- and while engineers are brilliant- I hope by the end of this we decide engineers aren’t the ones who should be making the knowledge trees but that the SME’s should be.
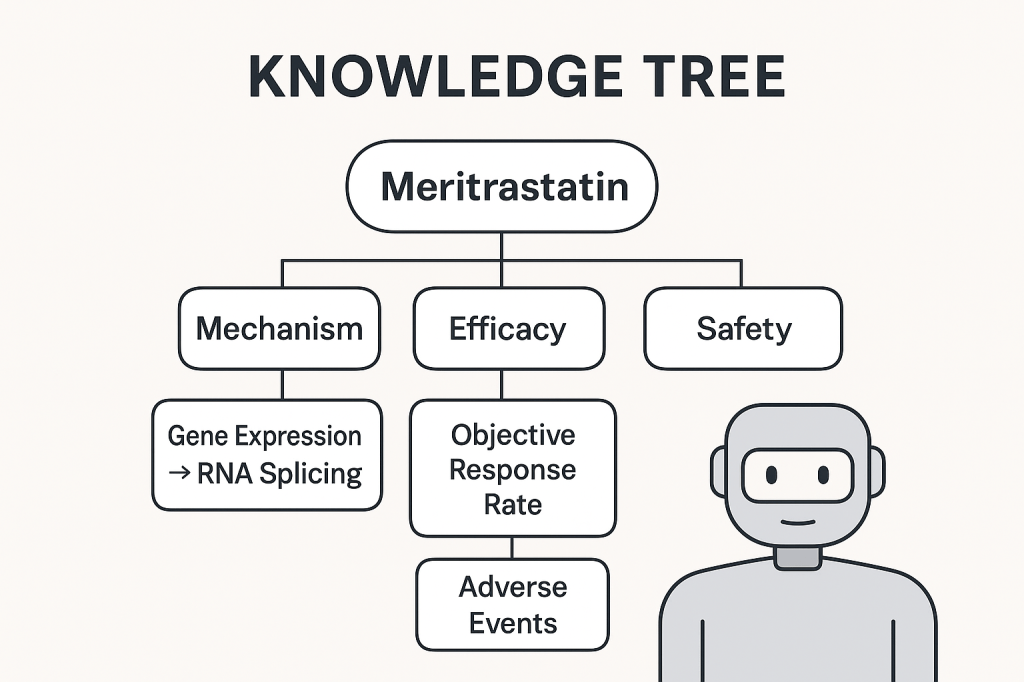
At a high level, a knowledge tree is a structured map of concepts, organized from general to specific, often with clearly defined relationships—like parent/child or cause/effect. Ontologies are similar, but they go further: they formalize the types of relationships between concepts, often using logic-based rules. They’ve long been used in fields like biology, library science, and enterprise knowledge management. But now, they’re becoming essential for something new: helping LLMs stop making things up.
Think of it this way—an LLM is like an incredibly eloquent student who has read every book in the library, but who has no idea which facts are current, connected, or even real. A knowledge tree is like giving that student a well-organized curriculum, complete with a syllabus, trusted textbooks, and a map showing how all the ideas relate. Suddenly, instead of guessing what might be true based on linguistic patterns, the model has grounding.
This grounding is especially important when LLMs are used in applications where accuracy matters—healthcare, law, education, science. When a model can anchor its responses in an ontology or knowledge graph, it’s far less likely to invent answers or mix up concepts. You can even design your system so that the model queries specific nodes in a knowledge tree during generation, pulling in only what’s relevant and real.
That’s already happening with retrieval-augmented generation (RAG), where LLMs retrieve snippets of actual documents to use as context. But ontologies take it further. They don’t just provide context—they provide structure. They tell the model what relationships are valid, what terms are synonymous or distinct, and what logical rules must hold. That structure can be used not just during retrieval, but during training, prompting, and even in post-processing validation. You can constrain outputs, guide reasoning steps, or fine-tune on synthetic examples generated from the tree itself.
For example, if your ontology says that mammals don’t lay eggs, then your model can be nudged away from ever saying that a dog does—even if it saw that idea somewhere online. If your knowledge graph shows that France is a country and Paris is its capital, your model won’t mix up Paris, Texas with Paris, France unless the prompt clearly calls for it. Disambiguation becomes much easier when semantic relationships are explicit.
This approach also fits beautifully with chain-of-thought prompting. If you’ve ever tried to get an LLM to reason step-by-step, you’ve probably seen how quickly it can drift into nonsense. But if those steps are mapped onto nodes in a knowledge tree, the model has a clear path to follow. Each step corresponds to a real concept with defined properties, which makes logical reasoning far more stable.
To build this kind of system, you don’t need to reinvent the wheel. Many domains already have ontologies—medical, legal, scientific—and there are tools to help you create or adapt them. OWL and RDF are standard formats; Protégé is a widely-used editor. The key is integrating the ontology into your AI stack: not just storing it, but using it actively in prompting, retrieval, fine-tuning, and evaluation.
This isn’t just an academic idea. It’s where the future of AI is headed. The next wave of language models won’t rely on scale alone—they’ll be hybrid systems, combining the flexibility of neural networks with the rigor of symbolic reasoning. We’re already seeing early signs of this in enterprise and research settings, where structured knowledge is used to reduce hallucination, improve explainability, and increase user trust.
In short, LLMs need more than just data—they need knowledge. Not just facts, but structure. Not just associations, but meaning. And that’s exactly what ontologies and knowledge trees provide.
If we want language models to be more than eloquent guessers—if we want them to be reliable collaborators in fields that matter—then we need to give them something better to stand on. A knowledge tree might not look impressive next to a trillion-parameter model, but it might just be the thing that keeps it honest

Leave a comment